实现模式
概述
这是一本小书,也是一个好书。
“我惊讶的发现,尽管能够快捷流畅地做出各种编程中的决定,但我没法解释自己为什么如此确定诸如“这个方法为什么应该被这样调用”,或者“那块代码为什么属于那个对象”之类的事情”。这本书在我看来就是解释这些个东西的。
这本书《实现模式》最大的跨度只到类一级,与之相比,设计模式则主要是在讨论类与类之间的关系,”本书的深度应该介于Design patterns和java语言手册之间”。
全书分为7大块,如下图所示
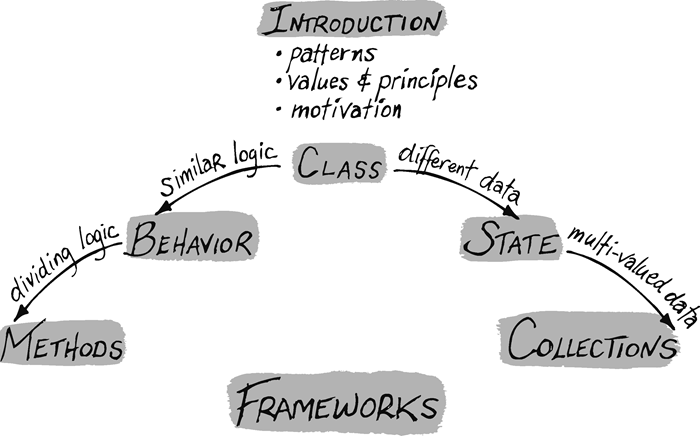
第一块,总体介绍,几个简短的章节描述了“用代码进行沟通”的重要性和价值所在,以及实现模式背后的思想。自认为是最重要的一块。沟通、简单和灵活这三条价值观为模式提供了广泛的动机。局部化影响、最小化重复、将逻辑和数据捆绑、对称性(匀称性)、声明式表达和变化率这6条原则帮助我们将价值观转化为实际行动,然后开始介绍各种模式。
第二块,类,这部分讲述了为什么要创建类,如何创建类,如何用类来书写逻辑等问题
第三块,状态,关于状态的存取的模式
第四块,行为,这部分模式告诉阅读者如何用代码来编写逻辑,特别是如何用多种不同的方式来做这件事
第五块,方法,关于如何编写方法的模式,他们将告诉你,根据你对方法的分解和命名,阅读者会作出怎样的判断。
第六块和第七块没怎么看,不说了。
这篇文章是这本书的读后感,要求2,3,4,5这几个模块的每个模式尽量都要落实到工作中所接触到的例子,真真切切感受其好处。
总体介绍
价值观
沟通、简单、灵活
更多的时候,程序是在被阅读而不是被编写。使用模式可以帮助程序员用更合理的方法来解决常见问题,从而把更多时间、精力和创造力留下来解决真正独一无二的问题。
模式描述了要做什么,价值观提供了动机,原则把动机转化成了实际行动。
原则
-
局部化影响
组织代码结构时,保证变化只会产生局部化影响,减少变化所引起的代价。(逻辑足够内聚,而不是散落在各处,散落在各处就要维护其一致性)
-
最小化重复
- DRY,重复代码,
- 并行的类层次结构。如果修改一处概念,需要修改两个或者更多的类层次结构就标识变化的影响已经扩散了。
-
将逻辑和数据捆绑
在发生变化是,逻辑和数据很可能会同时被改动,如果把他们放在一起,那么修改他们所造成的影响就会只停留在局部。(数据和逻辑要在一起,小到类,大到系统都是如此)
-
对称性
- 抽象层次要统一
- 方法名尽量以方法意图来命名(而非实现方式,透漏给客户端的信息越少,就给你自己留有更多修改的可能性)
-
声明式表达
(感觉像是在说代码要注重表明意图,而不是说具体的实现方式,client不需要知道的,不需要告诉他。告诉client do what而不是how do)。
-
变化率
- 把具有相同变化率的逻辑和数据放在一起。
- 变化率同样适用于数据,一个对象中所有成员变量的变化率应该差不多是相同的。
- 只会在一个方法的生命周期内修改的成员变量应该是局部变量。
- 两个同时变化,但又和其他成员的变化步调不一致的变量可能应该属于某个辅助对象。
- 变化率也是对称性的一个应用,不过是时间上的对称。
动机
Cost(total) = Cost(develop) + Cost(maintain)
Cost(maintain) = Cost(understand) + Cost(change) + Cost(test) + Cost(deploy)
软件成本可以被分解为初始成本Cost(develop)和维护成本Cost(maintain),而维护成本往往是大头。
在维护时注重程序员之间的沟通,减少理解代码所带来的代价,清晰明确的代码会带来即时收益:代码缺陷更少,更易共享,开发曲线更加平滑。
类
类
-
数据的变化比逻辑的变化要频繁的多。
-
每个类其实就是这样一个声明:这些逻辑应该放在一起,它们的变化不像它们所操作的数据那么频繁,这些数据也应该放在一起,它们变化的频率差不多,并且由与之关联的逻辑来负责处理。
-
子类传递的信息应该是:我和超类很像,只有少许差异。子类不要覆盖超类的方法。
-
用类名来讲述代码的故事。
- eg. PayConfirmSuccessEventListener4Insurance
简单的超类名
-
类名要简短而有表现力,贴切的命名能引发连锁反应,带来更深入的简化和改进。“哦,我明白了,不就是个scheduler么!”
-
对于重要的类,尽量用一个单词来为它命名
限定性的子类名
-
子类的名字有两重职责
- 描述它像什么类
- 还要说明它们之间的区别。
- 重要性不及继承体系根上的超类或接口,值得牺牲简明来换取更好的表现力,通常在超类名的基础上扩展一两个词
- eg. PayConfirmEventListener EventListener。
-
子类也可以拥有一个简单的名字
- 继承只是用作共享实现的机制,并且子类本身就代表了一个重要的概念,那么这样的子类就应该被视为它自己继承体系的根,拥有一个简单的名字
- eg. List Collection
抽象接口
-
应该在确认无疑地需要灵活性时,才应该引入这种灵活性。
-
java有两种方式来表现抽象接口:超类和interface,他们在应对变化时的涉及的成本各有不同。
interface
-
接口的语义:这是我要完成的任务,除此之外的细节不归我操心。更多的反应的是一种能力。ps:Java语言提供的Cloneable和Serializable的都是空接口,这种空接口也称为标识接口,标识接口中没有任何方法的定义,其作用是告诉JRE这些接口的实现类是否具有某个功能,如是否支持克隆、是否支持序列化等。
-
对接口的改变是不被鼓励的。特别是已经有很多的实现方了,改动接口的成本难以估量。
-
接口的命名
- 如果把interface看做”没有实现的类”,那么就应该像类名一样地给它们命名(简单的超类名,限定性的子类名)
- 如果具体类的命名对于交流更重要,这种情况下,可以给interface的名字上加上“I”前缀
抽象类
-
java的interface对接口本身的变化支持不佳,一旦改变了interface,所有的实现类都必须同时修改。
-
抽象类的局限体现在实现类必须对其忠心不二,如果需要以另一视角来看待同一个实现类,就只能让它实现interface了。
-
interface和类继承体系不是互斥的,你可以提供一个接口说你可以使用这些功能,再提供一个超类说“这是一种实现方式”。
- eg. 模板方法
有版本的interface
- 和所有设计决策一样,interface还是有可能变化的,如果真遇到需要对interface进行扩展的尴尬局面,可以引入有版本的interface。
- eg. 加减乘除的接口,增加了幂运算
值对象
-
值对象的所有状态都应该在构造器中设置,其他地方不提供改变其内部状态的方式。对于值对象的操作总是返回新的对象,操作的发起者要自己保存返回的对象。
- 类声明为final的
- 类中所有属性为final的
- eg. ticket-trade-order中的CmdAndExecutorPair
-
会创建临时对象,但考虑整体成本,这种反对意见往往靠不住脚。
特化
- 相同的逻辑处理不同的数据, 不同的逻辑处理相同的数据
子类
-
多用组合,少用继承
-
缺点
- 如果发现父类中一些变化不太适用于子类,就需要先花点功夫把代码从继承关系中解开。
- 使用者必须先理解超类,然后才能理解子类
- 对超类的修改颇有风险,因为子类有可能依赖超类中某个微妙的属性
- 禁止过深的继承体系。
- 慎重考虑平行的继承体系,是否真的可以平行。
- 不能表现不断变化的逻辑,所表现的变化在创建对象时就已经清楚了。
实现器
- 面向接口编程。
内部类*
-
内部类被实例化时,它的对象会悄悄地获得创建它的那个对象。如果想访问后者的实例数据而又不想在两者之间建立显式的关联,这个特点就显得很方便了。
-
内部类并没有真正的构造函数,即使声明一个也没用。
-
将内部类声明为static,将内部类与其所处的对象完全分离
实例特有的行为
一旦各个实例有不同的行为,就需要在运行时观察或者分析数据流才能理解一个对象的行为。为了让代码容易被读懂,即便是实例特有的行为,也最好在对象实例创建之初就确定下来,以后不再改变。 * eg. 在构造函数中设置策略对象,而不是通过set方法来设置。
条件语句
-
if-else和switch是最简单的方式。
-
除了修改对象本身的代码之外,没有其他办法来修改它的逻辑。
-
条件语句的好处在于简单和局部化。
-
条件语句的增加会降低可靠性。
eg. 简单工厂,通过条件找对应的产品类。不同策略走不同的代码逻辑等等(简单的可以,复杂的最好用策略模式替代之)
委派
-
要让不同的实例执行不同的逻辑,另一种办法就是把部分工作委派给不同类型的对象;不变的逻辑放在发起委派的类中,变化的逻辑交给委派的对象。
-
发起委派常用的技巧: 把发起委派的对象作为参数传递给接受委派的方法(不一定哟)
- eg. DelegatingErrorHandlingRunnable spring-context包
可拔插的选择器
反射(尽量少用,框架用)
匿名内部类
- 只在一处使用,api极其简单
- eg. Runnable的run方法,Compartor的compare方法
库类
-
某些功能放在哪些对象中都不合适,可以弄一个空类,在其中创造静态方法,任何人都不应该创建这个类的实例,它只用来安放这些功能
-
不适合大量使用,把所有逻辑都放在静态方法中就错过了使用对象的最大好处,把数据放入私有命名空间以便简化逻辑,应该尽量把库类变成合格的对象
- eg. DateUtils
状态
对象包装了行为和状态,前者被暴露给外部世界,后者则为前者提供支持。对象的好处之一便是将程序中所有的状态分割成小块。每一块都有属于自己的计算环境。
状态
-
函数式编程语言根本不允许改变状态
-
把系统的状态细分到各个小块中,每个小块的访问都是受到严格限制,从而可以避免状态“在背后偷偷改变”的问题。
-
有效管理状态的关键在于,把相似的状态放在一起,确保不同的状态彼此分离。对应前边提到的变化率的概念
- 它们在同一个计算中被用到
- 它们出现和消亡的时间相同
访问
“访问存储值”和“执行计算”,访问内存状态相当于调用一个函数,后者返回当前存储的值,调用函数相当于读取一个内存位置,并对其中的内容进行计算。但不管怎么说,我们的编程语言确实对两者做了区分,因此我们需要清晰的表述它们之间的差异
直接访问
- 只在访问器方法,构造器中使用直接存储,只在类及其子类,类所在的包的内部使用直接存储。
eg. this.name = name
间接访问
-
除上条的使用者,其他的使用者必须间接访问。
-
如果一个对象的某个状态的大部分访问都来自该对象之外,这就说明还有设计问题隐藏在更深的地方。
eg. 其他都是调用getter、setter或者其他具名的方法
通用状态
-
把具备相同变化率的数据项声明为一个类中的字段。(很多逻辑会涉及同样的数据项,应该把他们共同的数据项声明为一个类中的字段,而不是不加区别的全部罗列)
-
一个对象中所有的通用状态应该具有同样的作用域和生命周期。 有时我们被诱惑着引入一个这样的字段:它只被对象中的一小部分方法使用,或者只有在某个方法被调用的过程中有效,每当遇到这种情况,我总能找到一个更好的地方来保存这部分数据(可能是一个参数或者一个辅助对象),从而改善代码质量
eg.
-
InputWebContextParam中包含InputUserInfo,InputChannelInfo,InputFillOrderInfo, InputPayInfo 将具备不同变化率的数据项分类,
-
不需要在CreateParam中添加是否异步参数,是否异步生单和真正的生单参数有不同的变化率
可变状态
-
同一个对象需要不同的数据元素–不仅是数值改变,就连对象中的数据元素也全然不同,尽管这些对象都来自同一个类。
-
可变状态通常用map来保存,其中的key是数据元素的名字(变现为字符串或者枚举类型,我更偏爱枚举),值是数据值。
-
如果遇到一个字段的状态决定了同一个对象中是否需要其他字段,这种情况下就应当使用可变状态。
-
如果几个变量有相同的前缀,这可能意味着应该引入某种辅助对象,(变化率相同,对类信息进行合理归类)
eg. 窗体是否有框,可以使用通用状态,也可以使用可变状态,也可以使用多态。 todo
外生状态
- 对于特殊用途的信息,应该保存在使用该信息的地方,而不是保存在对象内部。
todo
变量
-
代码的阅读者需要知道变量的作用域,生命周期,角色和运行时类型
-
变量按照其作用域分为三种类型
- 局部变量,只能在当前作用域中使用
- 字段,可以在对象内的任何地方访问
- 静态字段,该类的所有对象都可以访问
-
可选的修饰符有public,package,protected,private
-
应该尽量保证变量的生命周期与作用域一致,此外还应该尽量保证兄弟变量(在同一个作用域中定义的变量)有相同的生命周期
-
用于容纳多个值的变量的名字应该是复数形式的,对于阅读者来说,一个变量包含的一个值还是多个值是非常重要的信息
-
如果作用域、生命周期和类型都能用别的方式充分描述,名称本身就可以只用于描述变量在计算逻辑中扮演的角色。把需要承载的信息减到最少,就可以选择简洁易读的名称了。
局部变量
-
遵照“信息最小扩散”原则,应该在尽可能靠内的作用域以及确实需要时才声明局部变量
-
局部变量常扮演的角色有以下几种:
- 收集器,用变量来收集稍后需要的信息,收集器的内容经常作为返回值传出,如果需要将收集器返回,就将它命名为result或者results
- 计数, 这是一种特殊的收集器,专门用于记录某些其他对象的个数
- 解释,如果一个复杂的表达式,可以把表达式的一部分结果赋值给一个局部变量,从而帮助阅读者理解整个复杂的运算
- 解释型局部变量往往可以再向前走一步,变成辅助方法,表达式变成方法体,局部变量的名字则是给方法命名的线索。
- 有时引入辅助方法只为了简化主方法,有时它们还而已消除类似的表达式中的重复代码。
- 复用,如果一个表达式的值会不断变化,而你又需要多次使用同一个值,就应该将这个值保存在局部变量中。eg 。Date now = new Date();
- 元素,局部变量最后一个常见的用途就是在迭代遍历集合时指代其中的元素
字段
-
我更愿意在阅读代码时首先看到数据的声明,“我也是”
-
可以选择把字段声明为final,以此告诉阅读者,构造函数执行完之后就不能再改变该字段的值了. eg. OrderCreationContext 中的orderDisplayId字段
-
字段承担的几种常见角色
- 助手,助手字段用于存放其他对象的引用,该对象会被当前对象的很多方法用到,如果有一个对象以参数的方式传递给很多个方法,就可以考虑改为通用助手字段(而不是参数)获得所需的对象,并在构造函数中给助手字段赋值。
- 标记,boolean型的标记表示“这个对象可能有两种不同的行为方式”。如果这个标记再有setter方法,那就表示“而且行为可能在对象生命周期中发生改变”
- 策略,如果想表达“这部分计算有几种不同的方式来进行”,就应该把一个“只执行这部分可变的计算”的对象保存在一个字段中。如果计算方式在对象生命周期中不发生变化,就在构造函数中给策略字段赋值,否则就提供一个方法来改变策略字段的值
- 状态,状态字段和策略字段有相似之处,它们所在的对象都会把一部分行为委派给它们,但状态字段在被触发时会自己设置相关的状态,而策略字段即便会发生改变,这改变也是由其他对象来进行的。用状态字段实现的状态机会很难理解,因为状态和变迁不在同一个地方描述
- 组件,这样的字段用来保存所在对象“拥有”的对象或者数据。
参数
-
由于非私有变量会在类与类之间造成强耦合,而且这种耦合会与日剧增,所以只要可能,就应该尽可能使用参数来传递状态
-
参数是将对象联系起来的细线,但是足够多的细线也能把一个对象束缚起来动弹不得,所以如果一个对象给另一个对象的很多消息都需要同一个参数,那么也许更好的办法是把这个参数永久地交给被调的对象
收集参数
有时计算逻辑需要从多次方法调用中收集结果,并将这些结果以某种方式合并起来,如果“合并结果”较复杂,传入一个参数来收集结果就显得更直观了。
eg. meilv中请求tradecenter的参数构造,TradeCenterOrderRequestBuilder
可选参数
- 套筒型参数列表
变长参数
- 变长参数必须位于参数列表的最后,如果一个方法既有变长参数,又有前面介绍的可选参数,那么可选参数也必须放在变长参数的前面
参数对象
-
如果同一组参数被放在一起传递给了很多个方法,就应该考虑创建一个对象,把这些参数放入该对象的字段,然后传递这个对象。
-
参数对象的引入让代码变得更短,意图更清晰。
-
尽管引入参数对象的主要目的是提高可读性,但参数对象也可以成为逻辑的重要去处,同一组数据在几个参数列表中出现,这本身就明白无疑的说明“这一组数据是强关联的”
常量
- 禁止出现魔法值,可以避免整整一大类的错误,是封装变化的很好体现。
按角色命名
- 变量名应该体现变量中的数据会被如何使用,以及这些数据在计算逻辑中扮演什么角色, 其他关于这个变量的重要信息-生命周期、作用域和类型,通常从上下文中就可以找到。
声明时的类型
- 如果可能,把变量和方法的类型声明的宽泛一些会有好处,但降低一点宽泛程度、损失一点精确性来获取一致性,也是合理的权衡。
初始化
-
我们希望尽量在声明的同时初始化,如果初始化和声明放在一起,那么与这个变量相关的问题都能从这个地方找到答案
-
另一方面,性能总是需要考虑的,那些初始化成本很高的变量很可能需要在声明之后的某个时候才初始化。
及早初始化
- 可以保证变量在使用之前一定是被初始化过的
延迟初始化
- 延迟初始化给阅读者传递的信息是: 此处性能很要紧
行为
控制流
java属于一个控制序列被视为基本组织原则的语言家族。
- 相邻的语句依次执行。
- 条件子句让代码只在特定的情形下才会执行。
- 循环会重复的执行代码,消息被发送去激活一段子程序。
- 异常让控制权从调用栈中跳出
作为程序员,你要决定如何去表达心目中的这个流
- 表达成一个含有例外情况的主体流
- 表达成多个同样重要的流
- 两者混合
将控制流的小片段归类,让不想深究的阅读者先得到一个抽象的理解,同时又为需要深入领会的阅读者提供更详尽的细节。eg。 spring的initWebApplicationContext方法。
归类的方式:
- 可以把一组例程放在一个类中
- 可以把控制委托给另一个对象
主体流
要清晰的表达程序的主体流,用异常和卫语句去表达不寻常的或者错误的情形
消息
-
用对象编程的一个美妙之处是同样的过程还表达了更丰富的东西,对于每个方法,都可能存在一组相似单细节上有所差异的结构化运算。
-
而且,额外的好处是,在编写恒定不变的部分时不需要去确定那些未变体的细节
-
用消息作为基本的控制流机制等于承认了变化是程序的基本状态
-
尽可能清晰和直接的表达逻辑,并且适当地推迟牵涉到的细节,如果想编写出能有效传达信息的程序,这是一种重要的技巧。
eg. AbstractApplictionContext#refresh() spring-context包
compute() {
input();
process();
output();
}
选择性消息
-
广泛的使用选择性消息可以使代码很少出现明确的条件语句。每条选择性消息都是对未来扩展的一个邀请。面向接口。
-
如果一项运算不存在可能的变体,不要仅为了提供变体的可能性而引入方法
eg. 不同的下单流程,不同的参数构造流程,OrderRequestBuilder
双重分发
-
选择性消息能很好地表达一维的变量,如果需要表达两个相互独立的变量维度,可以级联两个选择性消息
-
总能够为多维逻辑找到更清晰的表达方式,桥接模式
eg.
displayShape(Shape shape, Brush brush){
shape.displaywith(brush);
}
Rectangle.displayWith(Brush brush){
brush.displayRectangle(this);
}
PostscriptBrush.displayRectangle(Rectangle subject){
....
}
分解性(序列性)消息
-
对于一个由很多步骤组成的复杂算法,有时候可以把相关的步骤组合到一起,然后发送一条消息去调用他们。这个消息的目的不是提供一个特殊化的手段,或者什么深奥的东西,它只是平凡的功能分解。消息在这里单纯是为了调用例程中的一些步骤组成的子序列.
-
分解性消息需要有描述性的名称。要让大多数阅读者仅从名字就能够得知子序列的意图。
反置性消息
- 一旦培养起对代码之美的嗅觉,从代码中得到的美感将是对代码质量的一种宝贵的反馈。
eg.
void compute(){
input();
helper.process(this);
output();
}
改造后:
void process(Helper helper){
helper.process();
}
void compute(){
input();
process(helper);
output();
}
邀请性消息
-
有时当你写代码的时候,会预期其他人将在子类中变动其中一部分运算,此时应发送适当命名的消息,去传达这种将来进行改进的可能性,这样的消息是在邀请程序员今后按照他们自己的意图去调整运算。
-
如果一个逻辑存在一个默认的实现。那么可令其成为消息的实现。如果不存在,那么可令方法成为抽象的,以便明确该邀请。
eg.
protect abstract CommonResponse doTicket();
解释性消息
- 解释性消息所调用的辅助方法会成为日后有价值的扩展点
- 我使用解释性消息的主要目的还是为了更清晰的传达我的意图
eg: 这个太多了,只要是你想添加行注释的,都可以通过提取方法的方式,明确其意图。还有ticket-trade-order中对各dependent的mark和unmark方法。对于有含义的判定条件,我也喜欢抽成方法。
flags |= LOAD_BIT;
setLoadedFlag();
void setLoadedFlag(){
flags |= LOAD_BIT;
}
异常流
- 应清晰地表达主体流,并在不模糊主体流的前提下尽可能清晰地表达这些异常路径,卫语句和异常是表达异常流的两种方式
卫语句
- 卫语句是一种表达简单和局部的异常情况的方式,它的影响后果完全是局部的
- 嵌套的条件语句孕育着错误,用卫语句改写的代码强调了处理请求的先决条件,而不需要用到复杂的控制结构。先决条件和主体逻辑分开,代码清晰,可读性强。
- 卫语句的一个变体是在循环中使用continue语句,意图同样是指出正常和异常处理之间的差别
异常
- 应尽可能用序列、消息、迭代和条件来表达控制流,但当不使用异常会令主体流的表达变混淆的时候则应使用异常
已检查异常
- 当程序非预期地终止时能够输出分析情况所需的信息,并告诉用户发生了什么事情。
- 当抛出异常的程序和捕捉异常的程序由不同的人编写的时候,抛出的异常未被捕捉的风险更大,任何一点沟通上的失误都可能导致猝然而且粗鲁的程序终止。
- 已检查异常很容易让方法声明的长度翻一番,而且在抛出者和捕捉者之间又多了一样需要去阅读和理解的东西,
异常传播
- 低层异常通常包含一些对分析问题有价值的信息,用高层的异常去包装低层的异常,这样当异常信息输出到比如日志的时候,能记下足够的信息来帮助寻找错误。
方法
将一个程序的逻辑分割哼许多方法,相当于告诉别人“这些逻辑片段之间的联系不紧密”。再把方法分门别类放进类中,把类分门别类放进包中,就是在进一步地传递同样的信息。把这段代码放进一个方法,把那段代码放进另一个方法,就是在告诉阅读者两端代码之间的关系不密切,阅读者可以分别阅读并加以理解。更进一步,方法的命名也是与阅读者沟通的机会,他可以告诉阅读者这段逻辑的目的何在,让阅读者免受实现的影响。阅读者通常单凭阅读方法的名字就可以一眼分辨出哪些是自己要找的。
将大段的计算分割成若干方法,在概念上是简单的:将应该放在一起的片段放在一起,将应该分隔开的片段分割开。
将程序划分成方法一般需要考虑几个因素:大小、意图和方法的命名。如果分成了太多太小的方法,那么思维的表达就变得过于琐碎,阅读者不容易理清楚。大少的方法又会导致代码重复,而且伴随着灵活性的损失。
组合方法
-
通过对其他方法的调用组合出新的方法,被调用方法应大致属于相同的抽象层次,跳跃的抽象层次破坏了代码的流畅性
-
代码作者将逻辑划分成方法的时候要同时满足走马观花和细嚼慢咽的需要,这是一项挑战。
-
大小合适的方法可以一丝不差的被覆盖,不需要把部分代码复制到子类然后修改,也不需要为了概念上属于一个整体的单个修改而覆盖两个方法todo
揭示意图的名称
-
应该从潜在调用者的想法触发,根据调用者使用该方法的意图来给方法命名,你可能还想再方法中传达其他信息,比如方法的实现策略,不过最好只在名称中传达意图,方法的其他信息可以通过其他的途径去传达
-
实现策略是最常出现在方法名称中的枝节信息。有时候保持克制是必要的,除非实现策略对用户有意义,否则应该把它从方法名称中拿掉。
-
调用代码是在讲述一个故事,好的方法命名会让故事讲述的更流畅
eg.
customer.linerCustomerSearch(String id);和customer.find(String id);
insert(bookInfo)和save(bookInfo)
方法可见性
-
选择可见性的时候要在两件事情之间进行权衡,二者的平衡是决定可见性时要考虑的核心问题。
- 未来的灵活性,狭窄的接口更便于未来的变化,最小知识原则!
- 调用对象的代价,过于狭窄的接口让对象的所有客户都被迫执行更多不必要的工作
-
public: 声明它的包之外也是有用的,同时意味着你接受了维护它的责任,要么保持方法不变,要么在改变之后负责修复所有的调用者,至少要通知调用它的程序员
-
package: 感觉基本不适用
-
protected: 子类,和package是正交的关系
-
private: 私有方法是对未来灵活性的最大保证
-
final: 声明成final意味着你虽然不介意别人使用它,但你不允许任何人改变它。
方法对象
- 建设有一个方法很长,又有很多参数,并且用了很多临时变量,如果直接提取其中一部分的办法来重构,提取出来的部分会很难命名,而且参数也很多,这时候可以考虑采用方法对象模式。
- 用方法的名称作为类名
- 在新类中为每个参数,局部变量和方法中用到的字段—建立新字段,保留他们在旧类中的名字(以后再修改)
- 建立一个构造器,参数包括原方法的参数以及方法中用到的原对象的字段
- 将原方法赋值成心累中的calculate()方法,就方法中用到的参数,局部变量和字段都变成了对新对象的字段的引用
- 想原方法的方法体替换成创建一个新类的实例并调用calculate()方法
- 如果原方法中对字段进行了设置,那么在calculate()之后加上相应的代码
-
随着一个个方法被提取出来,你会发现原来很难分清楚的子逻辑现在变成名字有意义的助手方法 eg.
complexCalculation() { ComplexCalculator calculator = new ComplexCalculator(); calculator.calculate(); mean = calculator.mean; variance = calculator.variance; }
覆盖方法
-
超类中的抽象方法明确地邀请实现着对这一段计算进行特殊化,而任何没有声明成final的方法,都意味着可以用一种变体去替换现有的计算。
-
覆盖一个方法并不表示要在新旧之间二选一。可以既执行子类的代码又通过调用super.method();调用超类的代码。注意子类方法中想这样的调用只应该调用超类中的同名方法。如果子类有时候调用自己的代码,有时候调用超类的各种方法,那么累会变得难以理解,并且很容易被破坏。
重载方法
-
用不同的参数类型声明同一个方法,所传达出来的意思是“这个方法参数有多重形式”
-
同一个方法名下有多个不同参数数量的方法(套筒型)
-
多个重载方法的目的应该是一致的,不一致的地方应仅限于参数类型,如果重载方法的返回类型不同,会让代码难以理解,最好为新的意图找一个新的名字,不同的计算应该有不同的名称。
方法返回类型
-
应该在符合意图的前提下选择尽可能抽象的返回类型
-
泛化的返回类型有助于隐藏实现。
方法注释
-
对于沟通良好的代码来说,很多注释完全是多余的,编写这些注释,以及维护注释与代码的一致性的代价,远高于它们带来的价值
-
如果方法注释是最合适的沟通媒介,那就写一个好注释吧。
助手方法
-
助手方法是组合方法的衍生产物,要想将大方法分割成若干小方法,就少不了这些小小的助手方法。
-
助手方法的目的是暂时隐藏目前不关心的细节,让你得以通过方法的名字来表达意图,从而令大尺度的运算更具可读性
-
助手方法一般声明为private的,如果打算允许子类进行微调,可以提升为protected
-
如果任由两三行代码一再重复,你不但丧失了通过精心选择的方法名来传达其意图的机会,修改起来也很困难。
eg.
调试输出方法
-
投入精力实现高质量的调试输出能得到很好地回报
-
防范对toString()的滥用,最好的办法是尽最大努力让对象提供客户需要的所有行为。
-
如果需要提供便于程序员使用的对象表示,则重载toString(),而其他用途的字符串表示请放在其他方法或单独的类中
转换
-
创建一个目标类型的新对象,然后从源对象复制信息。
-
只实现目标对象的接口而无需从源对象复制信息
-
为两个对象找到一个共同的接口,然后针对接口来编程
转换方法
-
如果需要表达类型相近的对象之间的转化,且转换的数量有限,那么应把转换表达成源对象中的一个方法。
-
转换方法引入了从源对象到目标的对象的依赖关系。如果原先不存在这样的依赖关系,仅仅为了转换方法而引入依赖是不值得的。
转换构造器
-
转换构造器把源对象当做参数输入,然后返回目标对象。
-
转换构造器适合用于将一个源对象转换成许多目标对象,因为转换构造器分散在各个目标对象里,不会全都堆积在源对象的代码中
创建
- 必须在清晰而直接的表达和灵活性之间取得平衡,才能有效得利用对象创建来表达信息
完整的构造器
-
对象需要先得到一些信息才能开始运算,为了与用户就先决条件进行沟通,可提供一个构造器,构造器将返回准备好执行运算的对象
-
通过提供无参数的构造器和一系列设置方法来创建对象,可以很好地满足灵活性的要求,但无法表达出对象必须拥有哪些参数组合才能正常工作
-
在实现完整构造器的时候,可以把所有构造器都转移到一个主构造器,在主构造器中完成所有初始化工作。
工厂方法
- 如果要完成的工作比单纯创建对象更复杂,比如要在缓存中记录对象或者在运行时决定创建哪一个子类的对象工厂方法就很合适。
内部工厂
容器访问器方法
如果对象里包含一个容器,那么应该为它提供什么样的访问方式呢?
-
为该集合提供一个取值方法,容器内容的内部状态可能在你不知情的情况下失效,为对象提供这样的万能接口等于错失了创建了一个丰富而意图明确的接口的机会
-
再返回之前将容器包装成一个不可修改的容器,但这种包装只是在编译器面前伪装成一人容器,试图修改包装后的容器将引发异常,运行时才能发现的。
-
为容器中的信息提供限制性,意义明确的访问途径
eg.
void addBook(Book arrival) {
books.add(arrival);
}
int bookCount() {
return books.size();
}
Iterator getBooks(){
final Iterator<Book> reader = books.iterator();
return new Iterator<Book>() {
public boolean hasNext() {
return reader.hasNext();
}
public Book next() {
return reader.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
}
}
布尔值设置方法
-
最简单的就是一个单纯的设置方法
-
如果调用参数不外乎true和fasle,因此可以分别为两种状态各提供一个方法,以增强接口的表达能力
查询方法
- 如果一个对象有很多逻辑都依赖于另一个对象的状态,可能意味着逻辑放错了地方
相等性判断
- equals() 和 hashCode()
取值方法
- 我对那些外部可见的取值方法一般都充满了厌恶,我们一般对于领域模型对象有getter和setter,其他还是要遵循逻辑和数据放在一起的原则。
设置方法
- 根据方法的意图来命名有助于代码的表达。
安全复制
-
要是有两个对象都意味自己可以独占的访问第三个对象,使用取值或者设置方法就可能出现别名问题。
-
别名问题是更深次的征兆,比如对于哪个对象哪块数据划分得不清楚。
eg.
List<Book> getBooks() {
List<Book> result = new ArrayList<>();
result.addAll(books);
return result;
}
void setBooks(List<Book> newBooks) {
books = new ArrayList<Book>();
books.addAll(newBooks);
}
参考

