HashMap
基于jdk1.7
类图
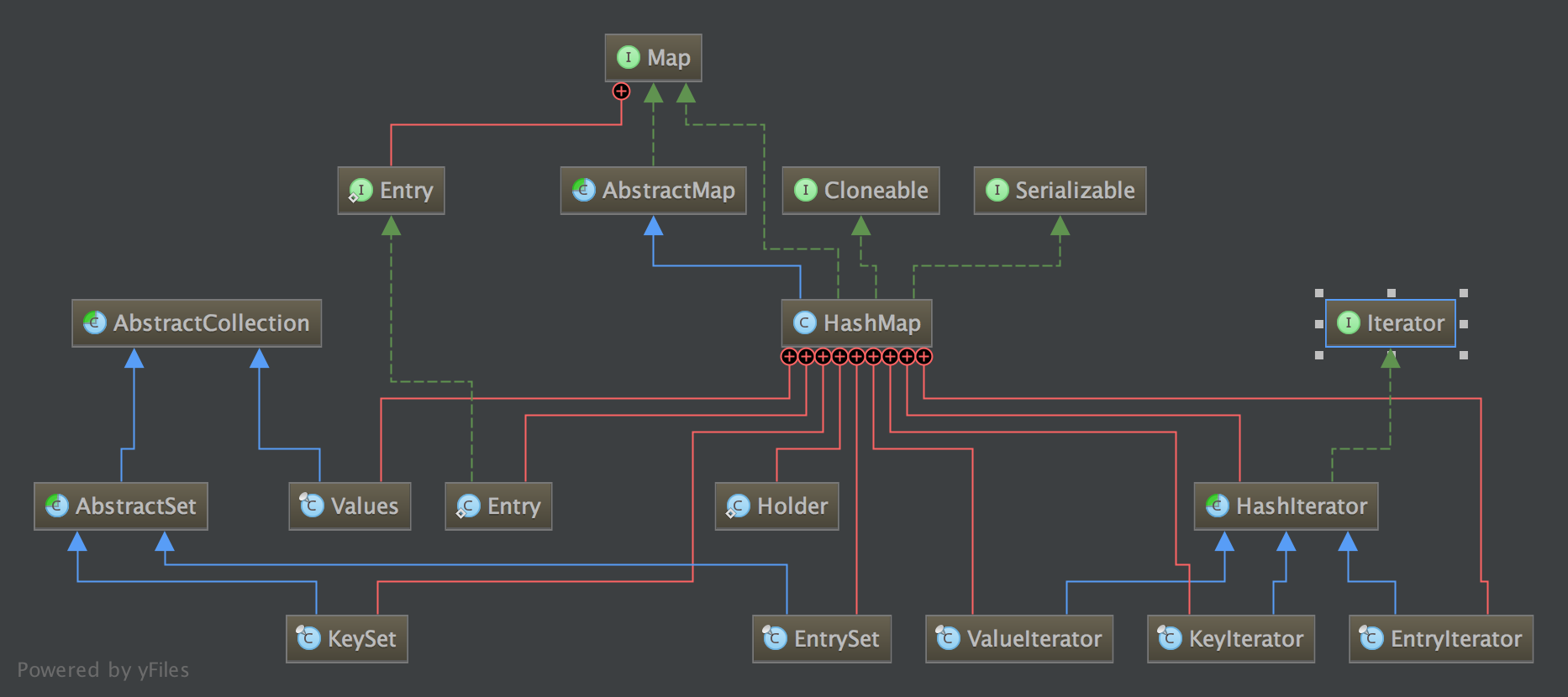
Map
Map内部子接口Entry (条目)
- size() 返回map的键值对数
- isEmpty() size()为0
- containsKey(Object key) 是否包含key
- containsValue(Object value) 是否包含value
- get(Object key) 返回key对应的value
- put(K key, V value) 添加键值对
- remove(Object key) 删除key对应键值对,返回value
- putAll(Map<? extends K,? extends V> m) 拷贝m到这个map中
- clear() 清空所有键值对
- keySet() 返回所有的key的 Set<K>
- values() 返回所有的values Collection<V>
- entrySet() 返回所有entry的 Set<Map.Entry<K,V>>
- Entry<K,V>
- getKey() 返回该entry的key
- getValue() 返回该entry的value
- setKey()
- setValue()
- equals(Object o) 重写equals方法
- hashCode() 重写了equals方法就要重写hashCode()方法
- equals(Object o) 重写equals方法
- hashCode() 重写了equals方法就要重写hashCode()方法,为什么?请看一道题目来说equals和hashCode
AbstractMap
对Map接口的方法进行实现,不对Entry接口进行实现,SimpleEntry(可变的) 和 SimpleImmutableEntry(不可变的),都是只有key value 两个属性
HashMap
HashMap 数据结构为数组(table[Entry])+ 链表(Entry.next),其Entry四个域,key,value,next,hash
HashMap几个比较重要的域
threshold阈值,代表hashMap存放内容数量的一个临界点,if ((size >= threshold) && (null != table[bucketIndex])),就需要resize,也就是新建一个两倍大的数组,并将老的元素转移过去。threshold = (int)(capacity * loadFactor);loadFactor负载因子,通常情况下threshold = capacity * loadFactor,默认大小为0.75size()map中键值对数capacity()table.length,桶的个数- Entry<K,V>[] table hashMap的table
数组存放Entry,next链表解决冲突
HashMap九个内部类
- Holder
-
Entry hashMap的Entry长这样,
链表final K key; V value; Entry<K,V> next; int hash; // HashMap#hash(Object key)的值 - EntrySet entry的Set
- KeySet key的Set
- Values values的collection
- HashIterator 抽象的hash表的Iterator
- EntryIterator 继承HashIterator Entry的Iterator
- KeyIterator 继承HashIterator Key的Iterator
- ValueIterator 继承HashIterator Value的Iterator
HashMap X问
1.为什么并发下会死循环
hash死循环发生在两个或多个线程同时对hashMap resize过程中 transfer会造成entry和它的next反转.entry的next又指向了next,造成死循环,照着耗子叔叔的走一遍就清楚了.
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
2.为什么其内部table的length都是2的幂
什么,不一定是2的幂?
一定的. 详情见HashMap#inflateTable -> HashMap#roundUpToPowerOf2 -> Integer.highestOneBit
扩容也是乘以2. 那么为什么要这么做呢?
可以保证entry分配均匀,在这里有讨论详见这里
3.hashCode如何提高HashMap的性能
具体在在equals hashcode中有讨论详见这里
4.EntrySet为何能遍历所有键值对
当初这么想的,EntrySet最多也只是能遍历所有Entry,在冲突的情况下,每个Entry上可能挂多个键值对,怎么能遍历所有的键值对呢.它重写了iterator()方法啊,不是AbstractSet的iterator()啊。妈的,源码中没带@Override标签,这也告诉我们重写的方法时最好是带上@Override,这对于读代码的人,有好处没坏处。
简直二逼啊!还是mark下吧。
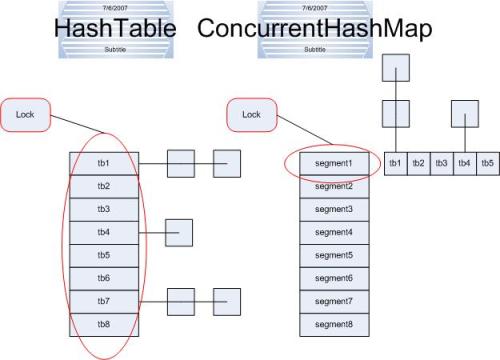
5.ConcurrentHashMap为什么线程安全且高性能
分段锁,减少锁粒度,避免对整张表加锁
参考
[1]http://mailinator.blogspot.com/2009/06/beautiful-race-condition.html
[2]http://coolshell.cn/articles/9606.html
[3]http://nanguocoffee.iteye.com/blog/907824
[4]http://blog.csdn.net/ns_code/article/details/36034955
[5]http://www.importnew.com/18633.html
[keySet 与entrySet 遍历HashMap性能差别]http://kim-miao.iteye.com/blog/736143
[Java 8系列之重新认识HashMap]http://tech.meituan.com/java-hashmap.html
[高性能场景下,HashMap的优化使用建议]http://calvin1978.blogcn.com/articles/hashmap.html
- 上一篇 mac使用
- 下一篇 java native调用

