java并发基础
- thread
- atomic
- ThreadLocal
- CopyOnWriteArrayList
- ReentrantLock
- volatile
- volatile_static_threadLocal
- ThreadExecutor
- lock、tryLock、lockInterruptibly
- Callable_Runnable
| 操作 | x86对应指令 |
|---|---|
| 测试并设置(Test-and-Set) | BTS |
| 获取并增加(Fetch-and-Increment) | INC |
| 交换(Swap) | BSWAP |
| 比较并交换(Compare-and-Swap,下文简称CAS) | CMPXCHG |
| 加载链接/条件存储(Load-linked/Store-Conditional,下问称LL/SC) | 这个x86系列的处理器好像木有,参见这里 |
thread
结合jvm内存模型
在Java当中,线程通常都有五种状态,创建、就绪、运行、阻塞和死亡。
| 状态 | 说明 |
|---|---|
| 创建 | 在生成线程对象,并没有调用该对象的start方法,这是线程处于创建状态。 |
| 就绪 | 当调用了线程对象的start方法之后,该线程就进入了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。 |
| 运行 | 线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行run函数当中的代码。 |
| 阻塞 | 线程正在运行的时候,被暂停,通常是为了等待某个时间的发生(比如说某项资源就绪)之后再继续运行。sleep,suspend,wait等方法都可以导致线程阻塞。 |
| 死亡 | 如果一个线程的run方法执行结束或者调用stop方法后,该线程就会死亡。对于已经死亡的线程,无法再使用start方法令其进入就绪。 |
- run()和start(): start方法会新起一个线程,而run方法只是普通的方法调用,还是在原线程。
- join()/join(long millis) 等待当前线程die或者超时
atomic
ThreadLocal
- 相当于线程范围的局部变量,Map<Thread,object>。
- 线程1set改变ThreadLocal的变量,不会影响线程2get该变量
- 业务处理完成之后一定要释放ThreadLocal的变量,对于使用线程池的,线程会复用,造成业务异常。
- ThreadLocal只是本线程有效,InheritableThreadLocal对由本线程创建的子线程也有效.
- InheritableThreadLocal remove时,子线程不会remove的,这点容易被开发人员不小心给忽略掉。
CopyOnWriteArrayList
ReentrantLock
ReetrantLock与synchronized
同:
- 线程重入特性
异:
- ReetrantLock是API层面的互斥锁,synchronized是原生语言层面的互斥锁
- ReetrantLock 等待可中断
- ReetrantLock 可实现公平锁
ReadWriteLock比ReentrantLock好在哪了,对于读读,ReadWriteLock是不加锁的,ReentrantLock还是会加锁滴.
volatile
volatile变量只能保证可见性,在不符合以下两条规则的运算场景下,我们仍然需要通过加锁(使用synchronized或者java.util.concurrent中的原子类)来保证原子性:
-
运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值
-
变量不需要与其他状态变量共同参与不变性约束。
volatile为什么能保证可见性,并不能保证原子性呢?
-
在volatile声明的变量赋值之后,然后立即使本cpu的cache写入内存,该写入动作也会引起别的cpu或者别的内核无效化其cache。所以通过这一空操作,可以让volatile变量的修改对其他cpu立即可见。
-
对主存中某变量来说,因为没有对其进行加锁,所以还是有多个线程同时操作,所以并不能保证原子性。
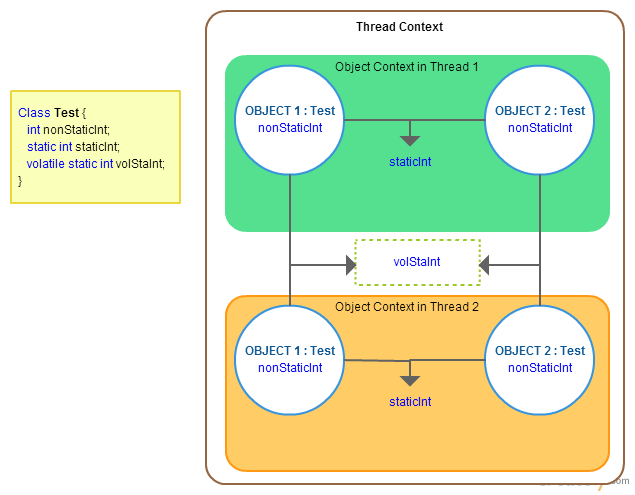
volatile vs static vs ThreadLocal
- volatile 不同线程的同一对象之间共享
- static 同一线程的不同对象之间共享
- static volatile 不同线程的不同对象之间共享他人的讨论
- threadLocal 同一线程之间共享,不同线程之间互斥,声明为ThreadLocal,通常需要声明为static,一个是per thread per object,一个是per thread,但对于单例的加不加就无所谓了。
eg:
public class DoubleCheckVersion {
private static volatile DoubleCheckVersion instance;
private InheritableThreadLocal<String> type = new InheritableThreadLocal<String>();
private DoubleCheckVersion() {}
public static DoubleCheckVersion getInstance() {
if (instance == null) {
synchronized (DoubleCheckVersion.class) {
if (instance == null) {
instance = new DoubleCheckVersion();
}
}
}
return instance;
}
public String getType() {
return type.get();
}
public void setType(String type) {
this.type.set(type);
}
}
ThreadExecutor
官方注释
@param corePoolSize the number of threads to keep in the pool, even
if they are idle, unless{@code allowCoreThreadTimeOut}is set
线程池中的线程数量,即使他们是空闲的,除非allowCoreThreadTimeOut设置了
@param maximumPoolSize the maximum number of threads to allow in the pool
线程池中的最大数量
@param keepAliveTime when the number of threads is greater than
the core, this is the maximum time that excess idle threads will
wait for new tasks before terminating.
当线程池中线程数量超过coreSize时,这是超出的线程能等待新任务的最长时间
也就是说keepAliveTime是在线程池中线程数量大于coreSize小于maxSize时起作用。
@param unit the time unit for the {@code keepAliveTime} argument
时间的单位
@param workQueue the queue to use for holding tasks before they are
executed. This queue will hold only the {@code Runnable} tasks submitted by the
{@code execute} method.
处理流程
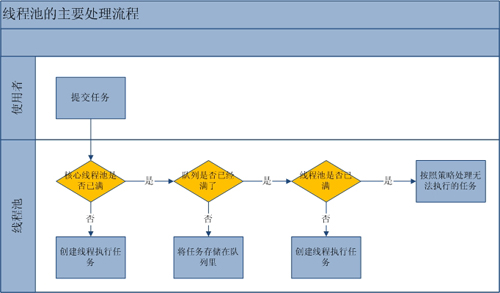
- 当coreSize未满时,当有新任务submit时,即使有空闲线程,也会新起线程。如果调用了线程池的prestartAllcoreThreads方法,线程池会提前创建并启动所有基本线程。
- 当coreSize满了,会添加到队列中
- 当队列也满了,但maxSize未满,会新起线程
- 超过maxSize,按照策略执行。
各线程池
- Executors.newFixedThreadPool(size)
- ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue
()); 线程池数量固定,无界队列,将保持所有线程running,直到被显式的终止,长时任务建议使用 - Executors.newCachedThreadPool()
- ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue
()) 线程池数量无界,SynchronousQueue一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue。 大量短时异步任务建议使用。 - Executors.newSingleThreadScheduledExecutor()
为什么要shutdown
试想一个daemon的线程池,其内部线程中又起了线程,在执行完task之后不shutdown。因为父线程持有子线程池的引用,并不会被gc掉,造成内存泄漏。 eg:
// executor使用的线程池,使用完毕时一定要释放。
// 验证:
// 主线程起一个scheduled的线程池,每隔1s触发一次,在子线程中也new一个线程池,提交任务之后
// 使用jvisualvm观察shutdown和不shutdown线程池数量的变化
@Test
public void whyShutDown() throws InterruptedException {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2);
AtomicLong atomicLong = new AtomicLong();
executorService.scheduleAtFixedRate(() -> {
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(() -> System.out.println(atomicLong.getAndIncrement()));
// shutdown ?or not shutdown ?
executor.shutdown();
}, 1, 1, TimeUnit.SECONDS);
Thread.sleep(100000);
}
lock、tryLock、lockInterruptibly
Lock接口,详见测试代码
ReentrantLock lock = new ReentrantLock();
- lock.lock()
- 不响应中断,即显示的调用thread.interrupt(),也不会中断lock.lock()加锁的进行
- 阻塞线程,直到拿到锁。
- lock.tryLock() 拿到锁则返回true,否则返回false。不阻塞线程
- lock.tryLock(x, TimeUnit.SECONDS) x秒内如果拿到锁,则返回true,否则返回false。x秒内阻塞线程
- lock.lockInterruptibly()
- 跟lock.lock()不同的是,它会响应中断,显示的调用thread.interrupt(),会中断lock.lockInterruptibly()加锁的进行,并抛出InterruptedException。
- 阻塞线程,直到拿到锁
Callable vs Runnable
- Callable可以返回值或者抛出异常,Runnable不能
- Callable接口是call,Runnable接口是run。
- Callable可以被ExecutorService#invokeXXX,但是Runnable不能;两者都可以被ExecutorService#submit调用。
参考:
[1]http://www.infoq.com/cn/articles/java-threadPool
[2]http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/Executors.html
[3]http://ifeve.com/java-concurrency-thread-directory/
[4]http://blog.csdn.net/column/details/concurrency.html
[java并发-ReentrantLock的lock和lockInterruptibly的区别]http://blog.csdn.net/wojiushiwo945you/article/details/42387091
[atomic_32.h]http://lxr.linux.no/linux+v2.6.26.6/include/asm-x86/atomic_32.h
[lock before try]https://stackoverflow.com/questions/10868423/lock-lock-before-try
[why a lock has to be followed by try and finally] https://stackoverflow.com/questions/6950078/threads-why-a-lock-has-to-be-followed-by-try-and-finally
- 上一篇 java序列化解析
- 下一篇 jvm性能工具(notes)

